TIL
내일배움캠프 본캠프 12일차 - 머신러닝 : 데이터 전처리, 의사결정나무 실습
수현조
2024. 12. 10. 20:19

오늘 한 것
1. 데이터 로드
train = pd.read_csv('./titanic/train.csv')
test = pd.read_csv('./titanic/test.csv')
- 동작: train.csv와 test.csv 파일을 Pandas의 DataFrame으로 불러옵니다.
- train: 모델을 학습하기 위한 데이터셋. 여기에는 승객의 생존 여부(Survived 열)가 포함되어 있습니다.
- test: 테스트용 데이터셋. 여기에는 생존 여부(Survived 열)가 없고, 모델이 예측한 값을 채워 제출해야 합니다.



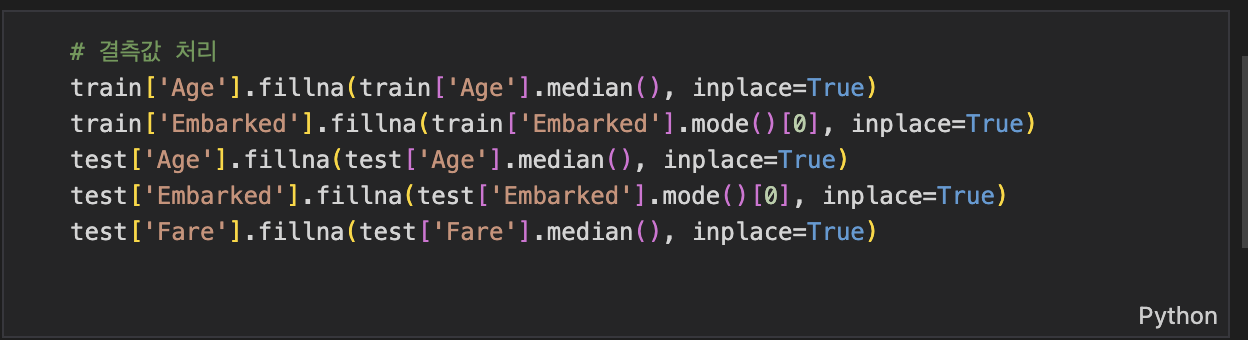
2. 결측값 처리
코드:
train['Age'].fillna(train['Age'].median(), inplace=True)
train['Embarked'].fillna(train['Embarked'].mode()[0], inplace=True)
test['Age'].fillna(test['Age'].median(), inplace=True)
test['Embarked'].fillna(test['Embarked'].mode()[0], inplace=True)
test['Fare'].fillna(test['Fare'].median(), inplace=True)
- 결측값: 일부 열(Age, Embarked, Fare)에는 데이터가 없는 행이 있습니다. 머신러닝 모델은 결측값이 있으면 학습하지 못하므로 이를 처리해야 합니다.
- fillna: 결측값을 특정 값으로 대체합니다.
- Age: 중간값(median)으로 채웁니다.
- Embarked: 최빈값(mode)으로 채웁니다.
- Fare: 중간값(median)으로 채웁니다 (테스트 데이터에만 해당).
3. 범주형 데이터 인코딩
코드:
train['Sex'] = train['Sex'].map({'male': 0, 'female': 1})
test['Sex'] = test['Sex'].map({'male': 0, 'female': 1})
train['Embarked'] = train['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
test['Embarked'] = test['Embarked'].map({'C': 0, 'Q': 1, 'S': 2})
- 왜 필요한가?
- 머신러닝 모델은 숫자 데이터만 처리할 수 있습니다. 문자열 데이터를 숫자로 변환해야 합니다.
- Sex 열: 성별을 0(남성), 1(여성)으로 변환.
- Embarked 열: 승선 항구를 숫자로 변환:
- C: 0 (Cherbourg)
- Q: 1 (Queenstown)
- S: 2 (Southampton)

4. 특징 선택
코드:
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
X_train = train[features]
y_train = train['Survived']
X_test = test[features]
- 특징(features): 모델이 학습에 사용하는 입력 데이터.
- Pclass: 티켓 클래스 (1등석, 2등석, 3등석).
- Sex: 성별.
- Age: 나이.
- SibSp: 동반한 형제/배우자 수.
- Parch: 동반한 부모/자녀 수.
- Fare: 운임 요금.
- Embarked: 승선 항구.
- 목표값(target): y_train은 승객의 생존 여부(Survived 열)입니다.

5. 데이터 분할
코드:
X_train_split, X_val, y_train_split, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
- 훈련 데이터와 검증 데이터로 분할
- 훈련 데이터: 모델 학습에 사용.
- 검증 데이터: 모델 성능 평가에 사용.
- test_size=0.2: 데이터의 20%를 검증용으로 사용.
- random_state=42: 데이터를 분할하는 방식을 고정하여 결과를 재현 가능하게 합니다.

6. 모델 학습
코드:
model = RandomForestClassifier(random_state=42)
model.fit(X_train_split, y_train_split)
- RandomForestClassifier: 여러 개의 의사결정 나무를 조합하여 예측을 수행하는 모델입니다.
- fit: 훈련 데이터(X_train_split, y_train_split)를 사용하여 모델을 학습합니다.

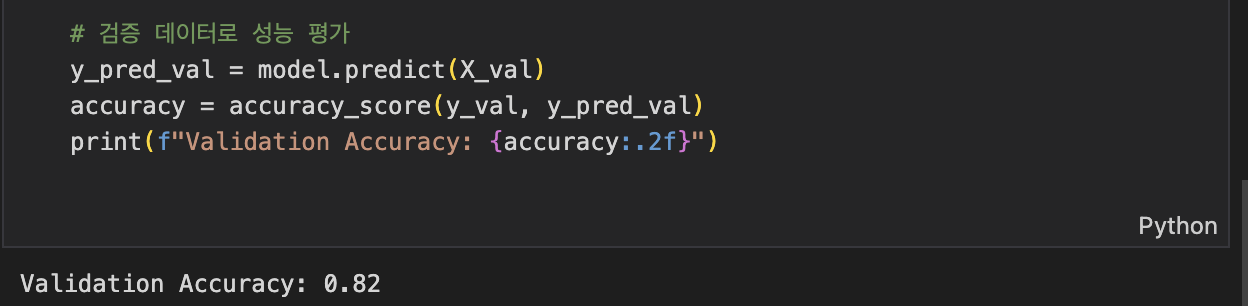
7. 검증 데이터 평가
코드:
y_pred_val = model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred_val)
print(f"Validation Accuracy: {accuracy:.2f}")
- predict: 검증 데이터(X_val)에 대해 생존 여부를 예측.
- accuracy_score: 모델의 정확도를 계산. 0.0~1.0 사이의 값을 반환하며, 1.0에 가까울수록 모델이 잘 동작하는 것입니다.
8. 테스트 데이터 예측 및 제출 파일 생성
코드:
y_test_pred = model.predict(X_test)
submission = pd.DataFrame({'PassengerId': test['PassengerId'], 'Survived': y_test_pred})
submission.to_csv('submission.csv', index=False)
테스트 데이터 예측
- X_test를 사용하여 승객의 생존 여부(y_test_pred)를 예측합니다.
제출 파일 생성
- Kaggle 제출 형식에 맞게 PassengerId와 Survived 열을 포함한 CSV 파일을 생성.

결과 요약
- 데이터 전처리를 통해 결측값을 처리하고, 문자열 데이터를 숫자로 변환했습니다.
- 주요 특징을 선택하여 학습 데이터를 구성했습니다.
- Random Forest 모델을 학습시키고 검증 데이터를 사용해 성능을 확인했습니다.
- 테스트 데이터를 예측하여 Kaggle에 제출할 준비를 마쳤습니다.
아니 일단. 이것도 이건데
오늘 좀 피곤해서 맥북으로 시도했더니
환경설정이 이상하다길래 다시 가상환경 만들고
다시 깔고 해도 vscode에서 넘파이가 없다는둥
계속 오류뜨고 지금도 씨름 중이다
저게 마지막 실행한 거다......
뭐가 문제인지는 알았는데 문제가 해결이 안되고 있다
근데 처음에는 왜 된거지? 이해가 안되네
가상환경 삭제했더니 더 엉망진창이 되어버렸다
다시 설치해도 다시 설치해도 다시 설치해도 파이썬이 없대!
나보고 어쩌라는거야 진짜 너무 짜증나 미쳐버릴거같다
눈이 너무 따갑다 오늘 이거 해결하고 잘거다
아오오오오오오오오오오오오ㅗ오오오 진짜 맥북 쥬거